

Wenn von Suchmaschinenoptimierung die Rede ist, wird irgendwann auch das Thema Content angeschnitten. Eine Website braucht gute Inhalte, um überhaupt in den Suchmaschinen Aufmerksamkeit zu erzeugen. Tatsächlich jedoch – und das dürfte für viele eine Überraschung sein – werden Texte in erster Linie nicht für die Suchmaschinen erstellt, sondern für den Benutzer. Oder wann hat eine Suchmaschine das letzte Mal mit Ihrem Text interagiert?
Es gibt unterschiedliche Ansätze, wie denn Inhalte für das Web verfasst werden sollen. Diese Ansätze zielen meist darauf ab, in den Suchmaschinen gut abzuschneiden und gute Platzierungen zu einer Vielzahl von Suchbegriffen zu sichern. Im Rahmen dieser „Best practices“ gehen die Content-Ersteller unterschiedliche Wege, um dieses Ziel zu erreichen. Und nicht selten konzentrieren sie sich dabei ausschließlich auf Keywords.
Das Zauberwort an der Stelle nennt sich „Keyword-Dichte“ und bezeichnet eine Größe, die den Grad der Disqualifizierung eines SEOs für seine Aufgabe bezeichnet. Und das ist durchaus ernst gemeint, denn wer heute noch mit diesem Wert arbeitet, hat SEO (und die Suchmaschinen) nicht verstanden.
Aber die Keyword-Dichte ist doch sooo wichtig
Ich höre schon, wie einige SEOs diesen Ausspruch in einem Anflug atemloser Entrüstung heraus blasen. Schließlich zählt bei den Inhalten doch nur, dass eine Unterseite für genau ein Keyword optimiert ist, welches auch noch in definiertem Maße in den Texten untergebracht ist. Wenn es etwa 4% aller Wörter einnimmt, dann ist es prima. Bitte nicht mehr, sonst ist es ja Spam.
Fein. Nehmen wir einen 300-Wörter-Standard-SEO-Text. Optimieren wir diesen auf den Begriff „Blaubauchtaubenhaucher“ (übrigens ein possierliches kleines Tierchen, welches nur in den Weiten dieses Dokuments lebt und mithin das einzige Wort, welches ich kenne, in dem vier „au“ vorkommen), dann muss dieser Begriff exakt 12 Mal vorkommen, um die 4%-Regel einzuhalten. Es stellt sich nur automatisch die Frage: bezogen auf was? Den Text? Alle Worte? Mit oder ohne die Wörter in Title und Description? Ja was denn nun?
Der findige SEO wird nun folgendes tun:
- Seitentitel: „Blaubauchtaubenhaucher – Beschreibung und Lebensraum“
- Description: „Informationen zum Blaubauchtaubenhaucher … bla bla bla“
- H1: „Der Blaubauchtaubenhaucher“
- H2: „Lebensraum des Blaubauchtaubenhauchers“
Und um das Drama perfekt zu machen, werden dann noch beliebige Absätze des ohnehin viel zu kurzen Textes mit dem Begriff vollgestopft. Gibt es hier nicht bessere Möglichkeiten?
Die SEO-Weltformel : WDF*IDF
Der heilige Gral der Suchmaschinenoptimierer besteht aus sechs Buchstaben, getrennt durch einen Asterisk (oder auch gerne mal ein Multiplikationszeichen). Doch was bedeutet diese merkwürdige Formel denn nun? Keine Bange, ich werde an dieser Stelle niemanden mit mathematischen Formeln bombardieren, die ohnehin mehr abschrecken als faszinieren. Und das schließt durchaus auch mich selbst mit ein.
WDF steht für „Within-document frequency“ und bezeichnet die Häufigkeit, mit der ein bestimmter Begriff in einem gegebenen Text auftaucht.
IDF hingegen steht für „inverse document frequency“ und ist weitaus komplizierter. Denn diese Größe beschreibt – stark vereinfacht ausgedrückt – die Gesamtzahl aller einem System bekannten Dokumente dividiert durch die Anzahl aller dem System bekannten Dokumente, die den betreffenden Begriff beinhalten. Daraus folgt: je weniger Dokumente einen bestimmten Begriff enthalten, umso wichtiger (= relevanter) wird das einzelne Dokument.
Und genau an dieser Stelle wird es spannend. Wer nämlich aufgepasst hat, wird entsetzt feststellen, dass wir unser hübsches kleines Dokument mit allen anderen Dokumenten im gleichen System in Beziehung setzen müssen. Das „gleiche System“ ist in diesem Falle der Suchmaschinenindex von Google, von Bing und von jeder anderen beliebigen Suchmaschine, die unser liebliches kleines Dokument indexiert hat. Nun hat aber nicht jeder Suchmaschinenindex die gleiche Anzahl an Dokumenten gespeichert und auch nicht die gleichen Dokumente. Viel Spaß beim Rechnen!
Der heilige Gral ist übrigens – wenn man es genau betrachtet – ein staubiger alter Becher. Ähnlich verhält es sich mit diesem System. Das WDF*IDF Prinzip gibt es nicht erst seit den Tagen des World Wide Web. Dieses Rechenmodell wurde bereits 1972 entwickelt. Warum dieses Modell für moderne Anwendungen vollkommen ungeeignet ist, zeigt Karl Kratz in einem wundervollen Artikel.
TF*IDF – The next generation
Irgendwann im Laufe der Zeit hat jemand festgestellt, dass WDF*IDF kein besonders guter Weg ist, um einem Dokument Relevanz einzubläuen. Es begann die Suche nach einer neuen Formel und irgendwann stieß jemand auf „TF“ – die „Term frequency“, eine neue Krücke für den Versuch, Texten das Hinken beizubringen.
Der Unterschied zur WDF besteht darin, dass das zu suchende Wort nicht in Relation zu allen anderen Worten im Dokument gesetzt wird, sondern lediglich dessen Häufigkeit gemessen wird. Es handelt sich also im Grunde um die Lizenz zum Wörter zählen. Damit aber das Spektakel noch lustiger wird, sorgt „IDF“ dann doch für die Relation zu allen anderen Dokumenten eines gegebenen Systems. Das einzig Positive an der Sache: die Anzahl aller Dokumente ist endlich und das macht es zumindest gefühlt überschaubar.
Warum Wörterzählen allein unsinnig ist
Nehmen wir an, wir schreiben unseren kleinen 300-Wörter-Aufsatz über den „Blaubauchtaubenhaucher“. In diesen verteilen wir „Blaubauchtaubenhaucher“ brav an 12 Stellen. Dann ist die Sache recht einfach, denn für unser Dokument haben wir eine TF von 12. Alle anderen Dokumente im Google-Index weisen für unser kleines Phantasiegeschöpf den TF=0 auf, denn auf so eine blöde Idee sollte noch niemand gekommen sein, was „Big G“ uns auch bestätigt.
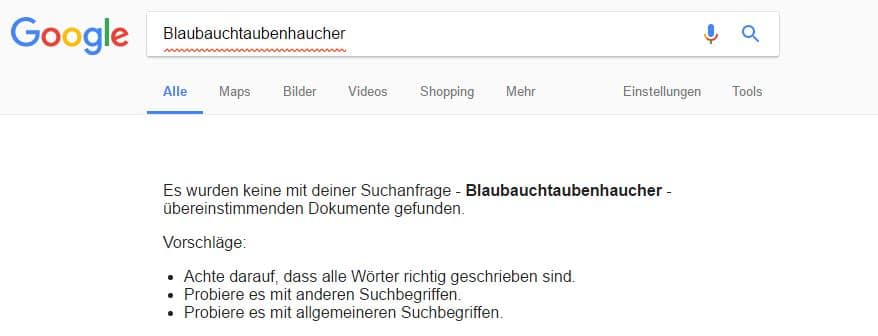
Jetzt ist es ziemlich wahrscheinlich, dass unser kleiner Aufsatz für den Suchbegriff enorme Relevanz besitzt, auch wenn das Wort nur ein einziges Mal darin vorkommt. Und wenn der Aufsatz nun „Acetylsalicylsäure“ zum Thema hätte?
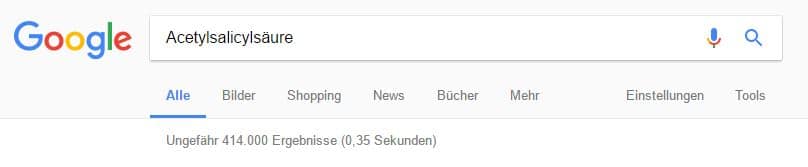
Dann müsste sich unser kleiner Aufsatz mit über 400.000 anderen Dokumenten anlegen. Und wenn hier keine bahnbrechenden Neuigkeiten zu vermelden gibt, sehe ich für unseren Artikel schwarz.
Aber warum sind diese Methoden der Relevanzberechnung überholt? Sowohl WDF*IDF als auch TF*IDF wurden für eine wortbasierte Suche geschaffen, um die Relevanz eines Dokumentes auf der Grundlage eines Begriffes oder einer Phrase zu bestimmen und eine Positionierung der betreffenden Dokumente in den Suchergebnissen zu ermöglichen. Nun ist z.B. Google so eine textbasierte Suchmaschine, denn wir rufen im Normalfall eine Website auf, geben einen Suchbegriff in das Eingabefeld ein und freuen uns dann über die ausgespuckten Ergebnisse – oder auch nicht. Wer aber bereits einmal eine moderne Suchmaschine benutzt hat, wird festgestellt haben, dass dort Suchergebnisse angezeigt werden, die so gar nicht nach der Keywordrelevanz geordnet sind.
Suchmaschinen arbeiten nicht mit der Keywordrelevanz
Das ist natürlich eine gewagte These. Denn im Umkehrschluss würde dies bedeuten, dass auch das einzelne Keyword sowie seine Häufigkeit im Dokument – wenn überhaupt – nur noch eine untergeordnete Rolle spielt. Testen wir dies doch einmal und nehmen als Suchbegriff das Wort „Relevanzberechnung“.
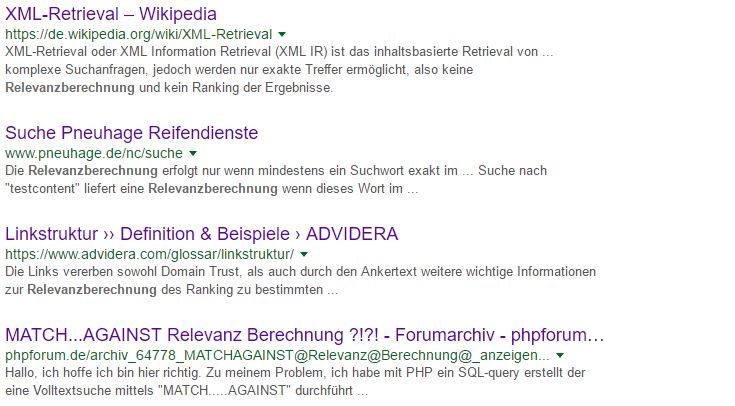
Dies sind die Suchergebnisse, die Google mir(!) für den Suchbegriff liefert. Die Nummer 1 habe ich absichtlich ausgelassen, da es sich lediglich um eine Website handelt, die eine englische Übersetzung des Wortes anbietet.
Betrachten wir einmal, was wir das als Ergebnisse bekommen haben. Insgesamt möchte Google uns 1370 Treffer für unser Suchwort anbieten. Und natürlich steht die Wikipedia ganz weit oben. Aber was ist das für ein Seitentitel? „XML-Retrieval“ soll eines der relevantesten Suchergebnisse für unsere Anfrage sein?
Um die Überraschung perfekt zu machen, zählen wir den Begriff „Relevanzberechnung“ im Dokument.

Unser Suchbegriff kommt exakt an drei Stellen im Dokument vor, davon an zwei Stellen in exakt gleicher Schreibweise. Insgesamt enthält das Dokument 808 Wörter. Das sieht ja nicht so aus, als ob die Worthäufigkeit hier so wichtig ist. Aber schauen wir uns das nächste Ergebnis an.
Zu unserer großen Überraschung finden wir hier keinen Artikel über die Methoden der Relevanzberechnung, sondern eine Anleitung für die Benutzung der Suchfunktion bei einem Anbieter für Autoreifen.

Immerhin findet sich unser Suchbegriff an gleich vier Stellen in exakter Übereinstimmung bei insgesamt 670 Worten mit Dokument. Das sieht großartig aus! Rein rechnerisch haben wir hier einen höheren Anteil des Suchbegriffes am Gesamttext als bei der Wikipedia. Dennoch hat diese Seite das Nachsehen und landet einen Platz dahinter.
Beim dritten Ergebnis wird die Sache noch mysteriöser, denn hier findet sich – in einem Artikel über Linkstrukturen – der Suchbegriff genau an zwei Stellen. Insgesamt kommen in dem Dokument mehr als 1.100 Worte vor.

Auch in diesem Artikel geht es nicht um Methoden der Relevanzberechnung. Und auch die Häufigkeit unseres Suchbegriffes ist hier kaum einer Erwähnung wert. Noch spannender wird die Sache allerdings beim letzten der vorgestellten Beispielergebnisse, denn in diesem kommt der Suchbegriff in exakter Schreibweise überhaupt nicht vor. An keiner Stelle in diesem Dokument, welches übrigens einen Thread aus einem Forum enthält, gibt es das Wort „Relevanzberechnung“.
Spätestens jetzt sollte bei jedem WDF*IDF-Fanatiker die rote Alarmleuchte aufblinken. Wie kann es möglich sein, dass eine textbasierte Suchmaschine ein Suchergebnis an Position fünf anzeigt, welches das gesuchte Wort nicht enthält? Naheliegend wäre die Argumentation, dass nicht nur exakte Treffer angezeigt werden, sondern auch ähnliche Begriffe. Und genau das wird auch in der Praxis berücksichtigt. Allerdings gehen die Algorithmen der Suchmaschinen noch viel weiter. Es spielt beispielsweise durchaus eine Rolle, welche Begriffe sich in unmittelbarer Nähe unseres Keywords befinden. Ebenfalls spielt es eine Rolle, ob es sinn- oder themenverwandte Begriffe in dem Dokument gibt. Und vor allem die Nutzerintention – abgeleitet aus der Anfrage – ist für die Ausspielung einer Website als Suchergebnis interessant
Drück Dich gefälligst deutlich aus!
Ich gebe zu, die gefundenen Ergebnisse für die Beispielsuche sind nicht wirklich aussagekräftig. Dies liegt allerdings auch in der Anfrage selbst begründet, die nun einmal lediglich ein einziges Wort enthielt. Und selbst eine hochentwickelte Suchmaschine fängt an irgendeiner Stelle an zu raten.
Stellen Sie sich vor, jemand steht vor Ihnen und sagt „Pudding“. Dann haben Sie diverse Möglichkeiten der Interpretation:
- derjenige möchte Pudding haben
- derjenige fragt, ob Sie Pudding haben
- derjenige heißt Pudding
- „Pudding“ ist eine südozeanische Grußformel
In letzterem Fall benötigen Sie ohnehin eine Übersetzungs-App. Ich denke jedoch, die Problematik an dieser Stelle ausreichend umrissen zu haben.
Eine Suche mit nur einem einzigen Wort tendiert in der Regel zu einer hohen Ungenauigkeit bzw. einer niedrigen Eindeutigkeit. Dies scheint auch in Nutzerkreisen immer bekannter zu werden, denn laut einer Studie des Unternehmens ahrefs bestehen nur noch rund 2,8% aller Suchanfragen aus einem einzigen Wort. Und genau dies ist auch ein Weckruf für alle SEOs und Content-Ersteller.
Der SEO-Text ist tot!
Der klassische SEO-Text konzentriert sich auf ein bestimmtes Keyword und versucht eine bestmögliche Optimierung auf dieses Keyword zu erreichen. Angesichts der Tatsache, dass mehr als 97% aller Suchanfragen aus mehr als einem Begriff bestehen und sich das Prinzip der Keyworddichte in einem Zustand fortgeschrittener Verwesung, dürfte die Fehlerhaftigkeit eines solchen Vorgehens deutlich werden. Daraus ergeben sich einige bedeutende Konsequenzen:
- das einzelne Keyword spielt für die moderne Suchmaschine kaum noch eine Rolle
- die Optimierung auf ein Keyword pro Unterseite ergibt keinen Sinn mehr
- Richtlinien wie „4% Keyworddichte“ und „Keyword in H1, H2 und diversen Absätzen“ wurden von der Zeit überholt
- die Suchintention des Nutzers ist der wichtigste Relevanzfaktor
Um es auf den Punkt zu bringen: der SEO-Text ist tot. Mehr noch ist es oftmals nicht einmal mehr relevant das gewünschte Keyword im Seitentitel unterzubringen. Tut es, wenn ihr euch dann wohler fühlt oder wenn das Thema es verlangt.
- Schreibt vor allem für die Nutzer der Website und nicht für die Suchmaschinen.
- Schafft Werte für die Besucher und vermittelt Informationen, ohne ständig darauf zu schielen, dass das Keyword auch in ausreichender Menge im Text vorkommt.
- Behandelt ein Thema, beleuchtet es von verschiedenen Seiten und stellt alle Aspekte eines Themas dar, ohne auf die Textlänge zu achten. Nutzt soviel Text wie nötig.
- Achtet nicht so sehr auf semantische Beziehungen im Text. Behandelt ein Thema von allen Seiten und ihr werdet verwandte Begriffe automatisch nutzen.
- Schreibt in natürlicher Sprache. Wer keywordoptimierte Texte schreibt, wird nicht natürlich schreiben und die Leser werden das bemerken.
Auch bei der Produktion von Inhalten gilt: setzt den Nutzer in den Mittelpunkt. Es ist schön, in den Suchmaschinen weit vorn gelistet zu werden. Am Ende werden es jedoch Menschen sein, die Vertrauen schenken, Produkte kaufen oder Informationen suchen.